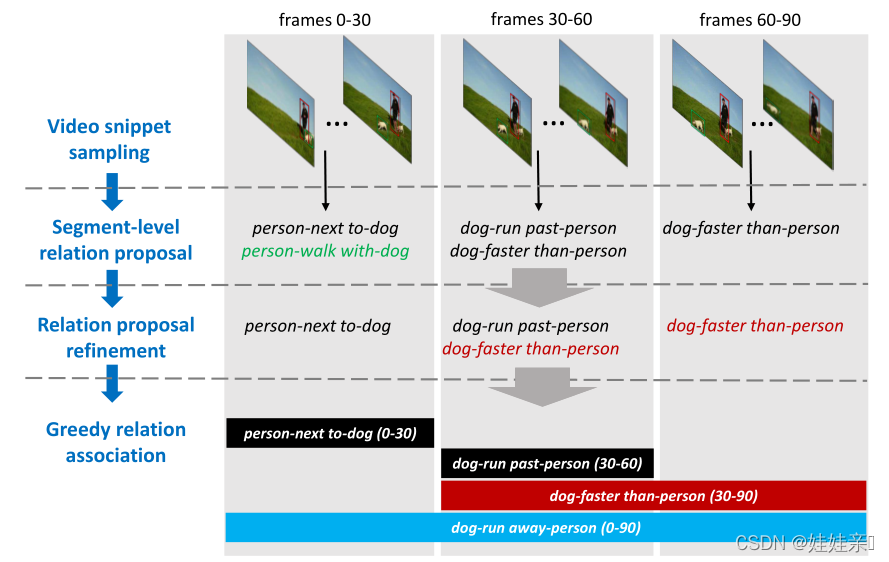
person-next to-dog (0-30)dog-run past-person (30...run away-person (0-90)1108400超越短期片段:具有时空全局上下文的视频关系检测0刘晨晨1,金阳2,徐科涵1,龚国强1,穆亚东1�01 北京大学,2 北京航空航天大学
”视频关系检测 滑动窗口方案 空间和时间信息利用 高度兼容的提议对 最先进的性能“ 的搜索结果
YOLOv1是属于One Stage:端到端目标检测。下面我们对其如何生成以及大致思路进行了解。思路首先将一幅图像分成SxS个网格(grid cell)(相当于将原图像进行SxS的裁剪,得到SxS个子图像,每个子图像进行单目标检测,...
滑动窗口就是能够根据指定的单位长度来框住时间序列,从而计算框内的统计指标。相当于一个长度指定的滑块正在刻度尺上面滑动,每滑动一个单位即可反馈滑块内的数据。 滑动窗口的意义 为了提升数据的准确性,将某个点...
具有许多对象的场景可能仅具有几个单独的交互对象(例如,在具有许多人聚会图像中,可能只有少数人在彼此交谈 为了检测所有关系,首先检测所有个体对象然后分类所有对将是低效的;不仅所有对的数量是二次的,而且分类...

信息科学与技术(TNList){runhaozeng.cs,ganchuang1990}@ gmail.com,[email protected],[email protected]摘要动作实例大多数最先进的动作本地化系统单独处理每个动作建议,而没有明确地利用它们在学习过程...
数据链路详解,包含了滑动窗口控制详解,滑动窗口信道利用率,差错控制,停等协议,连续ARQ,GBN,SR选择重传,HDLC
9964学习行动者关系图用于群体活动识别吴建超吴利民王晓莉王...此外,在实践中,我们提出了两种变体来稀疏ARG,以便在视频中进行更有效的建模:空间定位ARG和时间随机化ARG。我们在两个标准的群体活动识别数据集上进
我们的基准解决了三个问题:检测器和识别器的各种组合的性能,行人检测机制,以帮助提高整体重新识别(重新ID)的准确性和评估不同检测的有效性。(a) 行人检测…(b) 人员重新识别用于重新识别。我们有三个不同的贡献...
2,朱林超3,牟亚东1*01 北京大学,2 百度研究,3 ReLER实验室,AAII,悉尼科技大学[email protected],[email protected],[email protected]摘要0受益于深度卷积网络的进步,当前最先进的视频动作识别...
在训练数据中不需要时间动作边界注释的情况下,WS-TAL可以利用自动检索的视频标签作为视频级标签。然而,这种粗略的视频级监督不可避免地引起混乱,特别是在包含多个动作实例的未修剪视频中。为了应对这一挑战,我们...

1自适应NMS:改进人群中的行人检测刘松涛1,2,3黄迪1,2,3王云红1,31北京航空航天大学北京大数据与脑计算先进创新中心2北京航空航天大学软件开发环境国家重点实验室3北京航空航天大学计算机科学与工程学院,北京...

然而,这两种情况下 TCP 性能的最终结果是相同的:由于从接收器到发送器的 ACK 反馈的不完善和可变性,性能通常会显着下降。 该文件详细介绍了对这些影响的几种缓解措施,这些措施已在文献中提出或评估,或者目前已...
但是如果我们看一下在经典的视觉识别任务PASCAL VOC目标检测 [15]上的表现,普遍认为在2010年至2012年期间进展缓慢,只通过构建集成系统和使用成功方法的轻微变体获得了小幅增益。SIFT和HOG是基于块状方向直方图的...
7015掩模头结构对新颖类分割Vighnesh Birodkar,Zhichao Lu,Siyang Li,Vivek Rathod,JonathanHuang Google{vighneshb,lzc,siyang,rathodv,jonathanhuang}@ google.com摘要当在大型注释数据集上训练时,今天的...



YOLO已成为机器人、无人驾驶汽车和视频监控应用的核心实时目标检测系统。我们全面分析了YOLO的演变,研究了从原始YOLO到YOLOv8、YOLO-NAS和带有Transformer的YOLO的每次迭代的创新和贡献。我们首先描述了标准指标和...


2014年之前可以称为传统目标检测时代,其最具代表性的方法有VJ检测器[19]、HOG检测器[20]、DPM检测器[21]。它们有着共同的特点就是使用手工设计的特征描述子如方向梯度直方图[20](Histogramof Oriented Gradient,...
使用在imagenet上预训练的1000分类CNN,然后在voc数据集上选择性搜索出2000个区域提案区域...2000候选框图片进行resize,使得min(w,h)=sbackbone提取特征分类和回归:分类:SPP 4层FC层SVM分类器回归:BBox回归NMS。
同时,在无人机大量使用的背景下,其拍摄的图像和视频中包含用户感兴趣的小目标。在公开数据集中,一般认为小于32×32像素的目标为小目标。如果所有小目标检测都是手动执行的,则会消耗大量的人力和资源。
为了后续更好的阐述本文所提出的方法和对实验的分析,在详细介绍本文的工作内容之前,本章节先对本文涉及到的相关理论知识和关键技术做出简要概述。目标检测技术通常指在一张图片中检测出各个物体的位置及对应的类别...
在本教程中,我们将了解对象检测中称为“选择性搜索”的重要概念。我们还将用C ++和Python共享OpenCV代码。 物体检测与物体识别 对象识别算法识别图像中存在哪些对象。它将整个图像作为输入,并输出该图像中存在的...
因此,科学界认为深度学习是一种对加密流量进行分类的高性能方法。该文提出了一种基于深度学习技术的加密流量分类方法CBS。CBS 可以使用 1D-CNN、基于注意力的 Bi-LSTM 和 SAE 深度网络模型在两个级别对加密流量进行...
推荐文章
- Ubuntu/linux下下载工具_ubuntu下载软件助手 linux版本-程序员宅基地
- HTML、JSP前端页面国际化(i18n)_html全局国际化-程序员宅基地
- Python高级-08-正则表达式_写出能够匹配只有下划线和数字还有字母组成(且第一个字符必须为字母)的163邮箱(@1-程序员宅基地
- 寻仙手游维护公告服务器停服更新,寻仙手游2月1日停服更新公告 2月1日更新了什么...-程序员宅基地
- 用python自动预约图书馆座位_微信图书馆座位秒抢脚本-程序员宅基地
- Android真机或模拟器激活Xposed框架的方法_de.robv.android.xposed.installer-程序员宅基地
- 操作系统为什么要分用户态和内核态_用户态和内核态都需要cpu参与,为什么要区分-程序员宅基地
- 01—JVM与Java体系结构(简单介绍)_01_jvm与java体系结构.pptx-程序员宅基地
- 国有建筑企业数字化转型整体解决方案_建筑企业数字化转型行动方案-程序员宅基地
- 性能测试的软件------loadrunner_loadrunner有有三个图标,-程序员宅基地